
Calculadora da Taxa Interna de Retorno - TIR no Python

import numpy_financial as npf
import pandas as pd
from sympy import Symbol
def TIR08(lista):
"Argumentos: lista de listas"
#Convertendo a lista em dataframe
df = pd.DataFrame(lista,
columns = ["Ano", "Fluxo de Caixa"])
print(df)
#Definindo um símbolo para taxa de juros
i = Symbol("i")
#Calculando o valor presente
df["VP"] = (df["Fluxo de Caixa"])/((1+i)**df["Ano"])
print(df)
#Explicitando a conta que estamos fazendo.
eq = df["VP"].sum()
print("\nA conta é:", eq, "= 0")
#Criando uma lista com os fluxos de caixa a partir
#da lista original:
fluxos = [fluxo[1] for fluxo in lista]
print("\nOs fluxos de caixa são: ", fluxos)
#Calculando a TIR
TIR = npf.irr(fluxos)
print("\nA TIR é: ", round(100*TIR,2), "%")
#Criando uma lista com os dados.
#A lista deve ser composta por sublistas
#contendo a data e o fluxo na data.
lista08 = [[0,-800], [1, 200], [2, 250], [3, 300], [4, 350], [5, 400]]
TIR08(lista08)
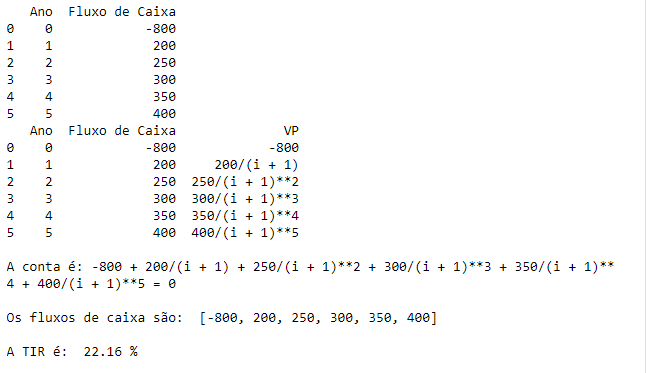
import numpy_financial as npf
import pandas as pd
from sympy import Symbol
def TABLE09(lista, i):
#Convertendo a lista em dataframe
df = pd.DataFrame(lista,
columns = ["Ano", "Fluxo de Caixa"])
print(df)
#Calculando o valor presente
df["VP"] = (df["Fluxo de Caixa"])/((1+i)**df["Ano"])
print(df)
#Soma dos valores presentes
VPL= df["VP"].sum()
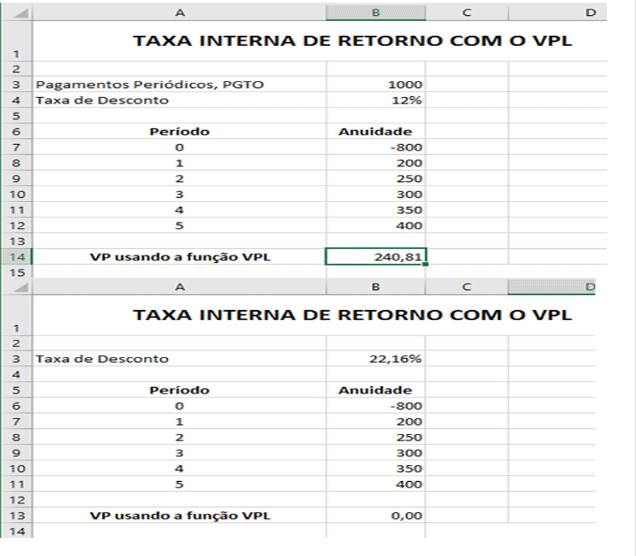
print("Valor Presente: ", round(VPL,2))
#Criando uma lista com os dados.
#A lista deve ser composta por sublistas
#contendo a data e o fluxo na data.
lista_09 = [[0,-800], [1, 200], [2, 250], [3, 300], [4, 350], [5, 400]]
TABLE09(lista_09, 0.12)
import numpy_financial as npf
import pandas as pd
from sympy import Symbol
def TIR10(lista):
df = pd.DataFrame(lista,
columns = ["Ano", "Fluxo de Caixa"])
print(df)
for j in range(-10000, 10001):
i = j/10000
df["VP"] = (df["Fluxo de Caixa"])/((1+i)**df["Ano"])
VPL = df["VP"].sum()
if -0.1<= VPL <=0.1:
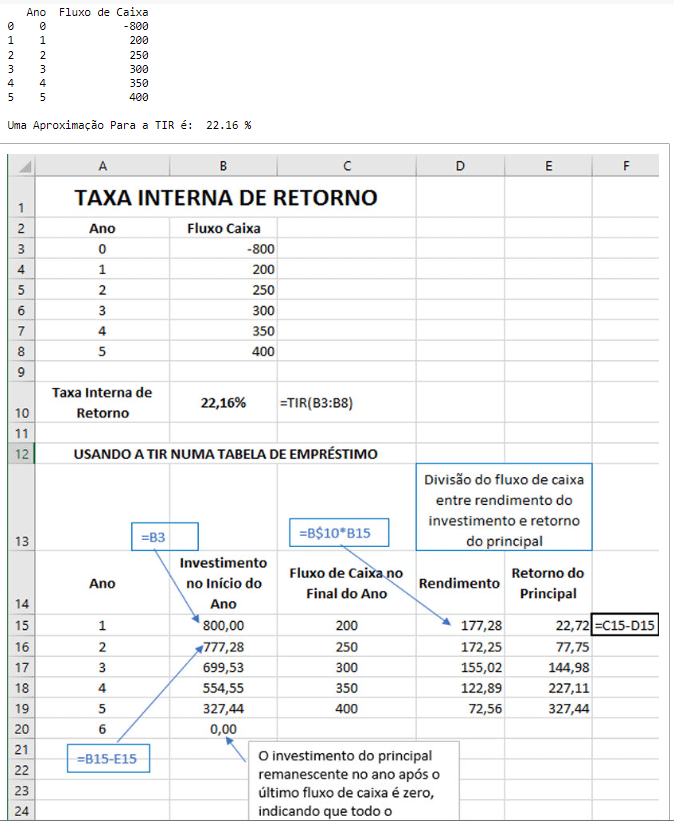
print("\nUma Aproximação Para a TIR é: ", i*100,'%')
#Criando uma lista com os dados.
#A lista deve ser composta por sublistas
#contendo a data e o fluxo na data.
lista_10 = [[0,-800], [1, 200], [2, 250], [3, 300], [4, 350], [5, 400]]
TIR10(lista_10)
import numpy_financial as npf
import pandas as pd
from sympy import Symbol
def TIR11(lista):
"Argumentos: lista"
#Criando uma lista com os fluxos de caixa a partir
#da lista original:
fluxos = [fluxo[1] for fluxo in lista]
print("Os fluxos são: ", fluxos)
#Calculando a TIR com a função do numpy_financial
tir = npf.irr(fluxos)
print("\nTIR: ", tir)
#Criando o fluxo de caixa ao final de um ano
FCfa = [fluxo[1] for fluxo in lista[1:]]
print("\nOS fluxos de caixa são: """, FCfa)
#Criando a lista Investimento no início do ano.
#Adicionaremos novos valores a ela a medida que
#formos iterando sobre ela.
Iia = [-lista[0][1]] #Pega o valor 800
#Criando as listas de renda e retorno ao principal.
#A cada iteração, novos valores serão adicionados.
RENDIMENTO = []
Retorno_do_Principal = []
for (fcfa, iia) in zip(FCfa, Iia):
rendimento = iia*tir
RENDIMENTO.append(rendimento)
retorno_do_principal = fcfa - rendimento
Retorno_do_Principal.append(retorno_do_principal)
iial = iia - retorno_do_principal
Iia.append(iial)
ANO = list(range(1,len(lista)+1))
pd.set_option('display.max_columns', None) #Faz com que todas as colunas sejam impressas, sem truncagem.
pd.set_option('display.max_rows', None)
df1 = pd.DataFrame({"Ano": pd.Series(ANO), "Investimento no Início do Ano": round(pd.Series(Iia),2),
"Fluxo de Caixa no Final do Ano": round(pd.Series(FCfa),2), "Renda": round(pd.Series(RENDIMENTO),2),
"Retorno do Principal" : round(pd.Series(Retorno_do_Principal),2)})
print(df1)
print("\nO investimento após o último período é: ", round(df1.iloc[-1, 1],2))
#Criando uma lista com os dados.
#A lista deve ser composta por sublistas
#contendo a data e o fluxo na data.
lista_11 = [[0,-800], [1, 200], [2, 250], [3, 300], [4, 350], [5, 400]]
TIR11(lista_11)

import numpy_financial as npf
import pandas as pd
from sympy import Symbol
def TIR12(lista):
"Argumentos: lista"
#Criando uma lista com os fluxos de caixa a partir
#da lista original:
fluxos = [fluxo[1] for fluxo in lista]
#Calculando a TIR pela função do numpy para fins de comparação.
TIR = npf.irr(fluxos)
print("\nTIR usando npf.irr(): ", round(TIR*100,3), '%')
#Parte importante:
for j in range(-100000, 100001):
Iia = [-lista[0][1]]
RENDIMENTO = []
Retorno_do_Principal = []
FCfa = [fluxo[1] for fluxo in lista[1:]]
i = j/100000
for (fcfa, iia) in zip(FCfa, Iia):
rendimento = iia*i
RENDIMENTO.append(rendimento)
retorno_do_principal = fcfa - rendimento
Retorno_do_Principal.append(retorno_do_principal)
iial = iia - retorno_do_principal
Iia.append(iial)
if -0.01 <= Iia[-1] <= 0.01:
print("\nTIR usando a tabela de empréstimo: ", round(i*100,3),'%')
#Criando uma lista com os dados.
#A lista deve ser composta por sublistas
#contendo a data e o fluxo na data.
lista_12 = [[0,-1000], [1, 300], [2, 200], [3, 150], [4, 600], [5, 900]]
TIR12(lista_12)
